|
Mingyu Park I'm an artificial intelligence and robotics researcher at ETRI in South Korea. My research goal is to build real‑world robots that can perform precise control tasks with human‑level cognitive and generalizable abilities. I’m especially interested in developing practical methods and understanding underlying foundations for sequential decision‑making problems. My current mission toward this goal is to devise a general method for learning a unified policy that can generalize to diverse tasks, environments, and embodiments.
|

|
Research interestFormally, my research interest interleaves between offline reinforcement learning, self‑supervised learning, and foundation models. I'm also interested in research topics about physical intelligence that may enable robots to understand the underlying physical rules of the real-world. |
Recent News 📣 |
|
(Sep., 2025) I started working as a Post-master's researcher at ETRI! (Feb., 2025) I finally graduated the Master's degree with the robotics program at KAIST! (May, 2024) I attended to ICRA in Yokohama, Japan! (Aug., 2023) I participated in Elite Summer School in Odense, Denmark! |
Publications |
|
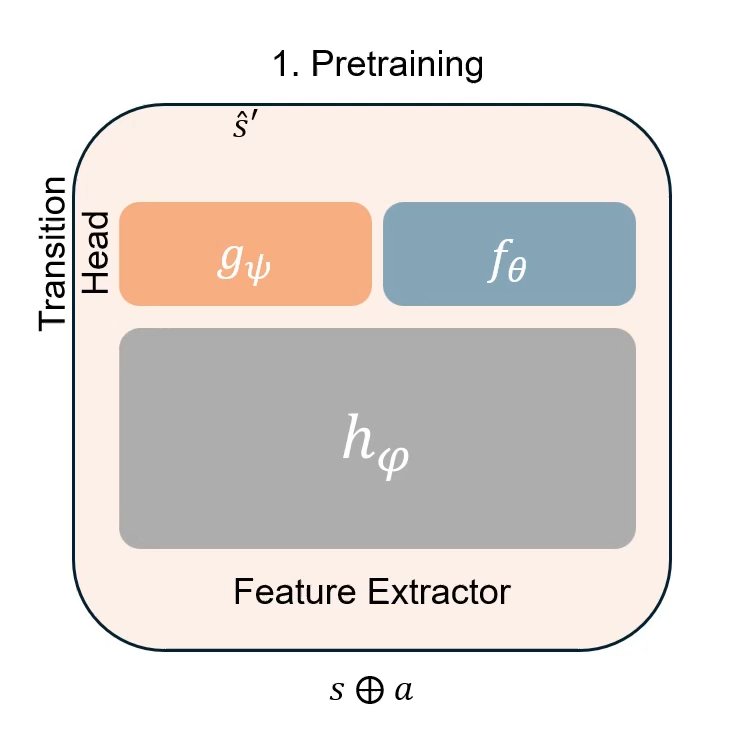
Pretraining a Shared Q-Network for Data-Efficient Offline Reinforcement Learning
Jongchan Park*, Mingyu Park*, Donghwan Lee† NeurIPS, 2025 (* equal contribution) paper / site Pretraining a shared $Q$-network with a supervised regression task significantly improves the performance of existing offline RL methods, demonstrating a strong data efficiency only with 10% of a dataset on the D4RL benchmark. |

|
Computational Cost Reduction Method for HQP-based Hierarchical Controller for Articulated Robot
Mingyu Park, Dongwhan Kim, Yongwhan Oh, Yisoo Lee† KROS, 2022 paper / site Reduced hierarchical quadratic programming (rHQP) is an optimal real-time controller for articulated redundant dual-arm manipulators. rHQP solves about x2.44 faster than the conventional HQP on average. |
Education |
|
KAIST(Korea Advanced Institute of Science and Technology) (Mar. 2023 - Feb. 2025) M.S. in Robotics Program |
|
|
Kwangwoon University (Mar. 2017 - Feb. 2023) B.S. in Robotics Engineering |
Work experiences |
|
ETRI(Electronics and Telecommunications Research Institute) (Sep. 2025 - Sep. 2026) Post-master's researcher at Digital Convergence Research Laboratory |
|
|
SNU (Seoul National University) (Jan. 2022 - Oct. 2022) Undergraduate Research intern advised by Prof. Jaeheung Park. Check details at project page! |
|
|
KIST(Korea Institute of Science and Technology) (Jun. 2021 - Dec. 2021) Undergraduate Research Assistant advised by Dr. Yisoo Lee. |
Extracurricular activities |
|
International Elite Summer School in Robotics & Entrepreneurship (Aug. 2023). Participated in the summer school to have a better academic knowledge of robotics, regarding advanced techniques for designing robotic systems and entrepreneurship in robotic startup companies (e.g. Universal Robots) in Denmark. |
|
|
BARAM (Academic Robotics Club) (Mar. 2020 - Dec. 2022) Designed and taught an academic seminar regarding robotics, including computer vision and control engineering. Check details at project page! |
Awards & Honors |
Awards
Honors |
{kind=link}
{kind=link}
Services |
Reviewing
|
|
Template is borrowed from here. |